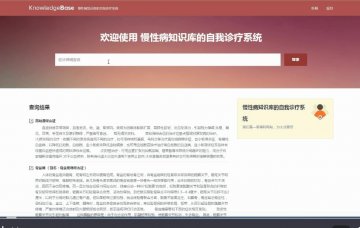
jsp1104慢性病知识库的自我诊疗系统mysql(150元)
- 模板售价:¥150.00元
- 成品编号:13java13me+jsp1104
- 使用技术:无
- 数据库:Mysql
- 最后更新:2018-11-20 16:36
注意:QQ2748904540,qq3300576459为本网站唯一售卖成品的账号,其他均为盗版
jsp1104慢性病知识库的自我诊疗系统mysql(150元)的大图展示
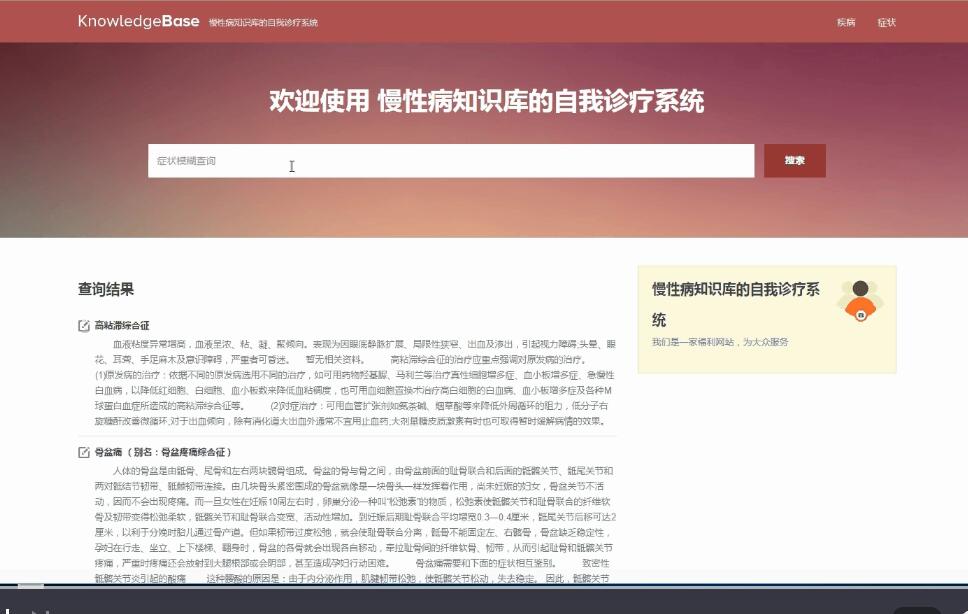

 全屏查看大图演示
全屏查看大图演示
计算机毕业设计源码网:我们提供的源码通过邮箱或者QQ传送,如果有啥问题直接联系客服
素材描述:本套java设计包含程序,0.5w字论文,演示视频
系统开发技术及实现的功能:
系统最主要最核心的部分就是慢性病知识库,数据库数据来源是通过网络爬虫实现,网络爬虫(Web Crawler),又称为网络蜘蛛(Web Spider)或 Web 信息采集器,是一个自动下载网页的计算机程序或自动化脚本,是搜索引擎的重要组成部分。网络爬虫通常从一个称为种子集的 URL 集合开始运行,它首先将这些 URL 全部放入到一个有序的待爬行列里,按照一定的顺序从中取出 URL 并下载所指向的页面,分析页面内容,提取新的 URL 并存入待爬行 URL 队列中,如此重复上面的过程,直到URL队列为空或满足某个爬行终止条件,从而遍历Web。 该过程称为网络爬行(Web Crawling)[5]。
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫 (Incremental Web Crawler)、深层网络爬虫 (Deep Web Crawler)。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
(1)通用网络爬虫又称全网爬虫(Scalable Web Crawler),爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。 由于商业原因,它们的技术细节很少公布出来。 这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,但需要较长时间才能刷新一次页面。 虽然存在一定缺陷,通用网络爬虫适用于为搜索引擎搜索广泛的主题,有较强的应用价值。
(2)聚焦网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler),是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。 和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。
(3)增量式网络爬虫(Incremental Web Crawler)是 指 对 已 下 载 网 页 采 取 增 量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。 和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。增量式网络爬虫的体系结构包含爬行模块、排序模块、更新模块、本地页面集、待爬行 URL 集以及本地页面URL集。
相关推荐
标签

全部评论 / 0